SQLによるDBマイグレーションの再設計 (KLabTechBook Vol. 16)
この記事は2025年11月2日から開催された技術書典19にて頒布した「KLabTechBook Vol. 16」に掲載したものです。
現在開催中の技術書典20にて新刊「KLabTechBook Vol.17」を頒布(電子版無料、紙+電子 500円)しています。 また、既刊も在庫があるものは物理本をオンラインマーケットやオフライン会場で頒布するほか、 KLabのブログからもすべての既刊のPDFを無料DLできます。 あわせてごらんください。
今回は久しぶりにオフライン会場にも出展します。「か07」でお待ちしています。

スキーマ管理とマイグレーションツール
スキーマの管理、どうしてますか? アプリケーションの開発が進むと同時に、DBのスキーマも変化していきます。 開発が進むたび、あるいはGitのブランチを切り替えるたびに、 どのような変更をDBに適用すべきかを手作業で追うのは簡単ではありません。 単純な適用漏れでDBとコードの整合性が崩れ、アプリが正しく動かないなんてこともあります。 本番環境でそんなことが起これば即障害です。
この問題に対処してくれるのが「マイグレーションツール」です。 これは、スキーマの定義や変更内容をアプリと同じ言語や独自のDSLでコードとして記述し、 それをDBへ適用することでアプリの状態とDBの状態を揃えてくれるツールです。 これによってスキーマをアプリのコードと一緒にバージョン管理することもできます。
マイグレーションツールはフレームワークやORMに組み込まれていることもありますし、独立したツールも存在します。 また、ORMやDSLでスキーマを記述することで、安全性を高めたり複数のRDBに対応しやすいというメリットもあります。
ORM/DSLの限界とSQLが必要になる場面
ORMやDSLは一見便利に見えるかもしれませんが、実際の運用ではそれだけでは対応しきれない場合があります。 いくつか例を見てみましょう。
データコピーを伴うテーブルの変更
たとえば、ユーザーごとに1つのメールアドレスを登録できるサービスがあるとします。 あるとき、「ユーザーが複数のメールアドレスを登録できるようにしたい」という仕様変更が入りました。
正攻法として正規化を行い、新しくemailsテーブルを追加してユーザーとメールアドレスを1:Nで管理します。
これをER図で表すと図1のようになります。
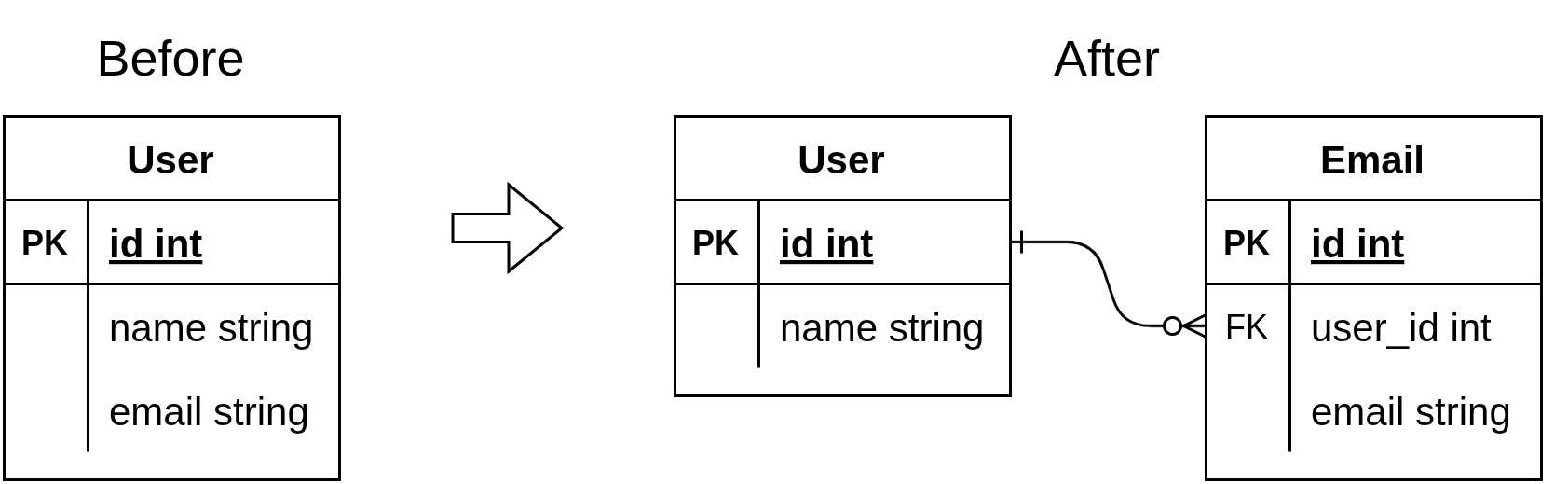
▲図1 スキーマの変更
テーブルを追加したあと、usersテーブルに登録済みのメールアドレスを新しいemailsテーブルにコピーし、
そのあとで古いカラムを削除します。
これをPHPのLaravelでマイグレーションする場合、リスト1のようになるでしょう。
▼リスト1: Laravelでのマイグレーション
return new class extends Migration
{
public function up(): void
{
// emailsテーブルを作成
Schema::create('emails', function (Blueprint $table) {
$table->id();
$table->foreignId('user_id')->constrained('users');
$table->string('email');
});
// 既存のemailデータをemailsテーブルにコピー
DB::table('users')
->whereNotNull('email')
->chunk(100, function ($users) {
foreach ($users as $user) {
DB::table('emails')->insert([
'user_id' => $user->id,
'email' => $user->email,
]);
}
});
// usersテーブルからemailカラムを削除
Schema::table('users', function (Blueprint $table) {
$table->dropColumn('email');
});
}
public function down(): void
{
// 省略
}
};
このマイグレーションスクリプトには、パフォーマンス上の問題があります。 既存のメールアドレスを新テーブルにコピーするために、アプリケーション側でデータを取得して1件ずつ挿入しています。 レコード数が多い場合、この処理は数分〜数十分かかることもあります。
SQLにはINSERT INTO ... SELECT構文があり、DB内部で直接データをコピーすることができます。
これを使ったSQLによるマイグレーションはリスト2のように書けます。
▼リスト2: SQLによるマイグレーション
-- emailsテーブルを作成
CREATE TABLE emails (
id int NOT NULL AUTO_INCREMENT,
user_id int NOT NULL,
email varchar(255) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY fk_user (user_id) REFERENCES users(id)
);
-- 既存のemailデータをemailsテーブルにコピー
INSERT INTO emails (user_id, email)
SELECT id, email FROM users WHERE email IS NOT NULL;
-- usersテーブルからemailカラムを削除
ALTER TABLE users DROP COLUMN email;
この方法ならデータをアプリケーション側に転送する必要がなく、さらに挿入クエリを多数発行する必要もありません。 また、DB内部でコピー処理が完結していて実行も最適化されるため、件数が多くてもせいぜい数秒〜数十秒で完了します。
Laravelに限らずORMやDSLの多くは、このようなSQL特有の構文をサポートしておらず、 必要に応じて生のSQLを記述する方法に頼ることになります。 結局のところ、性能要件を満たすためにはSQLを直接書くことが求められます。
ダウンタイムなしのオンライン変更
ある機能をリリースした直後に、想定以上にDB負荷が高まっていることがわかったとします。 調べてみると、特定のテーブルにインデックスを付け忘れていたことが原因でした。 単純にインデックスを追加すれば解消しますが、できればメンテナンスに入れることなく、 まだレコード数が少ないうちにオンラインで追加してしまいたいと考えました。
さて、リスト3のようなマイグレーションは、 果たしてオンラインでも安全に実行できるでしょうか。
▼リスト3: Laravelでインデックスを追加するマイグレーション
public function up(): void
{
Schema::table('highscore', function (Blueprint $table) {
$table->index('user_id');
});
}
public function down(): void
{
// 省略
}
おそらく内部では単純なALTER TABLE文が発行されると思われます。
しかし、それは本当にオンラインでの実行に耐えうるでしょうか。
安全のために広い範囲のロックが掛けられたりしないでしょうか。
このような懸念を払拭するには、最終的にどんなSQLが実行されるかを確認する必要があります。
さらに言えば、MySQLやPostgreSQLにはリスト4のような テーブルへの読み書きをブロックせずにインデックスを追加できる構文が用意されています。 これを使えばオンラインでも問題なく安全にインデックスを追加できるでしょう。
しかし、このような構文をORMやDSLがサポートしていることはほとんどなく、SQLを記述することになります。
▼リスト4: ブロックしないインデックスの追加
-- MySQLの場合。PostgreSQLでは"CREATE INDEX CONCURRENTLY"
CREATE INDEX idx_user ON highscore (user_id) ALGORITHM=INPLACE, LOCK=NONE;
ここまで2つの例を見てきましたが、性能や可用性を意識したマイグレーションを行うには、SQLを直接書く必要が出てきます。 また、安全なDB操作を実現するには、ORMやDSLで書かれたコードが最終的にどのようなSQLとして実行されるかを常に意識しなければなりません。
であるならば、最初からSQLですべて記述したほうが合理的ではないでしょうか。 そうすればDBのすべての機能を利用できるうえ、どのようなSQLが実行されるかも一目瞭然となり、挙動を完全に把握できます。
SQLによるマイグレーションの課題
これまでSQLでのマイグレーションを行いたくなる理由を述べてきました。 しかし、世の中にあまり普及していないのはなぜでしょうか。 FlywayやGooseのように SQLで記述するマイグレーションツールもありますが、あまり一般的ではありません。 SQLによるマイグレーションには多くの課題があるからです。
ここではそれらの課題を紹介し、どのように対処したらSQLのみでマイグレーションが実現できるかを考えていきます。
アプリケーションコードとの連携
ORMやフレームワークのマイグレーション機能は、アプリケーションコードと密接に統合されています。 テーブルの定義がそのままモデルクラスと直接対応していることも多く、 コードの変更とスキーマの変更を同時に管理できることが高い利便性となっています。
一方で、SQLによるマイグレーションではSQLがアプリケーションコードから独立するため、 モデルとテーブル構造を自動的に同期させることができません。
しかし、よく考えてみてください。 アプリケーションにとって必要なモデルは「クエリ結果を受け取るデータ構造」であって、 必ずしもテーブル構造と一致している必要はないのです。 リポジトリ層の内側がどのようなテーブル構造になっているかは、本来アプリケーションから隠蔽されるべきです。 すなわち、このような連携の不足は欠点ではなく、むしろ「責務の分離」であり、あるべき姿ともいえます。
アプリケーションからスキーマの定義を切り離し、モデルクラスの責務を明確に分けることが健全な開発につながります。 モデルの生成や型安全なアクセスが必要な場合、 sqlcのようなクエリからコードを生成するORMが良い解決策となるでしょう。
適用順序と履歴の管理
SQLでマイグレーションを記述する場合、スキーマに対する変更を積み重ねていくことになります。 ここで問題になるのは、各変更をどの順序で適用するか、そしてどこまで適用したかをどのように管理するかという点です。 管理を曖昧にしたままマイグレーションを実行すると、同じ変更を重ねて適用してしまったり、 適用順序を誤って整合性が崩れてしまうおそれがあります。
既存のSQL記述型のマイグレーションツールが解決しているのはこの問題です。 これらのツールでよく用いられているのは、 ファイル名にバージョン番号を含めることで順序を表し、DBに適用履歴テーブルを作って管理する方法です。 SQLだけでマイグレーションを行う場合も、この考え方をそのまま取り入れることができます。 ここではMySQL向けの具体的な手順を示します。
まず、適用履歴テーブルをリスト5のように定義します。
▼リスト5: マイグレーション適用履歴テーブル
CREATE TABLE _migrations (
id INTEGER NOT NULL,
applied DATETIME,
title VARCHAR(255),
PRIMARY KEY (id)
);
idは適用順序を表す番号とします。
各マイグレーションは必ずupとdownのペアとし、up.sqlにスキーマを更新するSQLを、down.sqlにはそれを元に戻すSQLを記述します。
たとえばid = 1で、create_tablesというタイトルのマイグレーションのファイルは次のようになります。
000001_create_tables.up.sql000001_create_tables.down.sql
2つのファイルに分けているのは、SQLを適用するときにファイル単位でDBに適用できるようにするためです。 ここまでは既存のマイグレーションツールと同様ですが、 履歴テーブルへの挿入や多重適用の回避もツールに頼らずSQLで行うようにするために、ファイル先頭にいくつかSQLを記述します。
▼リスト6: 000001_create_tables.up.sql
INSERT INTO _migrations (id, title, applied) VALUES (1, 'create_tables', NOW());
-- ここから下に適用したいSQLを記述
CREATE TABLE ... 省略
このSQLファイルをDBに適用すると、最初に適用履歴テーブルへの挿入が行われます。
このとき、すでに適用済みで同じidのレコードが存在している場合、
PRIMARY KEY制約によってこのINSERT文は失敗します。
この時点で処理が停止するため、続くCREATE文は多重に実行されることはありません。
一方で、down.sqlでは適用済みでレコードが存在するときのみ実行したいものです。
しかし単純にSELECTするだけでは、結果が0件でもエラーとはならずに、そのまま次のSQLが実行されてしまいます。
このような場合に処理を停止させるには、MySQLではリスト7のようなストアドプロシージャを使用します。
引数としてidを受け取り、同一idのレコードが存在しなかった場合にSIGNALでエラーを発生させるものです。
▼リスト7: マイグレーションが適用済みか確認するストアドプロシージャ
CREATE PROCEDURE _migration_exists(IN input_id INTEGER)
BEGIN
IF NOT EXISTS (SELECT 1 FROM _migrations WHERE id = input_id) THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'migration not found';
END IF;
END
down.sqlの先頭でこのストアドプロシージャを使って適用済みかどうか判定し、
適用済みだった場合にはレコードを削除してから目的のSQLを実行します。
▼リスト8: 000001_create_tables.down.sql
CALL _migration_exists(1);
DELETE FROM _migrations WHERE id = 1;
-- ここから下に元に戻すSQLを記述
DROP TABLE ... 省略
このようにすることで、どのマイグレーションが適用されているかは適用履歴テーブルを見ればわかり、
多重適用しようとしても適用前にエラーで停止するようになります。
これらのSQLは定型文なので、idとtitleからファイルを生成できるようにすると便利です。
この仕組みにより、一般的なマイグレーションツールと同等の履歴管理を、 外部ツールに依存せずにSQLだけで実現できます。
スキーマ全体像の把握
ORMやDSLでマイグレーションを記述する場合、モデルクラスやスキーマ定義ファイルを見れば最新状態の構造をひと目で把握できます。
一方でSQLでは、ALTER TABLE文のような変更を順に積み重ねていく形式になります。
この状態では、最終的にどのようなテーブル構造になっているか把握しづらく、開発やレビューの負担が増してしまいます。
マイグレーションSQLをすべて順に適用した結果のダンプがあればよいのですが、 これを都度作るのは手間がかかりるので自動化したいところです。
変更の可逆性の担保
マイグレーションにおいて、変更の可逆性は重要です。 本番環境の更新作業の切り戻しの際や、開発中Gitのブランチを切り替えたときにDBを適切な状態にするためには、 適用した変更を元に戻せる必要があります。
ORMやDSLを元にSQLを生成するようなマイグレーションツールでは、可逆性もある程度自動的に担保できるでしょう。 しかし、SQLを直接書くような場合は、書く人間が責任を持って可逆性を維持しなければなりません。 先に述べたように、ORMやDSLによるマイグレーションツールを利用していても、直接SQLを書く必要性が出てきます。 つまり、ほとんどすべてのマイグレーションツールが、この可逆性を完全には担保できていないのです。
もちろんSQLだけでSQL自身の可逆性を確認することはできません。 もしSQLの正当性・可逆性を確認することができるツールがあれば、 SQLでマイグレーションを記述することはアドバンテージにさえなりえます。
このためのツールとして「migy」を開発しました。
migyは自由なSQLで書かれたup/downのSQLファイルの正当性と可逆性をチェックするサポートツールです。
また、マイグレーション適用後の状態をSQLとしてダンプする機能も備えています。
これにより、可逆性を確認するとともにスキーマの最終状態を明確に把握することが可能になります。
それでは、migyについて詳しく紹介したいと思います。
SQLマイグレーション支援ツール「migy」
- GitHubリポジトリ: https://github.com/makiuchi-d/migy
migyは、SQLによるマイグレーションを支援するスタンドアロンツールです。 これまでに挙げた課題を解決するために開発されました。 migyは内部にMySQL互換のインメモリDBエンジンを持っているため、外部DBを用意しなくてもSQLを実行することができます。
ここでは、基本的な使い方をなぞりながら、migyがSQLによるマイグレーションの課題をどのように解決するのかを説明します。
1. init: セットアップSQLを生成
$ migy init
writing: 000000_init.all.sql
SQLによるマイグレーションの管理には、
リスト5で紹介した履歴管理テーブルと
リスト7の適用済みかどうかを確認するストアドプロシージャを用います。
initサブコマンドは、これらを定義するSQLファイル「000000_init.all.sql」を生成します。
このファイルと同じディレクトリに、続く更新SQL(up.sqlとdown.sqlのペア)を配置していきます。
2. create: マイグレーションSQLの雛形を作成
$ migy create add_users_table
writing: 000010_add_users_table.up.sql
writing: 000010_add_users_table.down.sql
createサブコマンドはup/downのファイルペアを生成します。
番号は自動的に採番され、ファイル先頭にはリスト6とリスト8で示したような、
管理テーブルへの挿入や削除を行うSQLが書き込まれています。
そのため、開発者はスキーマを更新するSQLの記述に集中できます。
それではリスト9のように更新SQLとしてCREATE TABLE文を記述してみましょう。
▼リスト9: 000010_add_users_table.up.sql
-- Generated by migy (https://github.com/makiuchi-d/migy)
INSERT INTO _migrations (id, title, applied)
VALUES (10, 'add_users_table', now());
-- Write your forward migration SQL statements below.
CREATE TABLE users (
id int NOT NULL PRIMARY KEY AUTO_INCREMENT,
name varchar(255) NOT NULL
);
down.sqlを書く前に、このマイグレーションの可逆性を確認してみましょう。
3. check: 可逆性のチェック
$ migy check
applying: 000000_init.all.sql
---- up/down
applying: 000010_add_users_table.up.sql
applying: 000010_add_users_table.down.sql
checking...
unexpected "users" table found
check failed
checkサブコマンドは、up/downを適用する前後でDBの状態を比較し、一致していない箇所を報告します。
実際にSQLを実行するので、文法ミスなどもチェックできます。
この例ではまだdown.sqlを書いていないので、予期しない"users"テーブルが存在することが検出されました。
それではリスト10のようにdown.sqlにDROP TABLE文を書いて、もう一度checkしてみます。
▼リスト10: 000010_add_users_table.down.sql
-- Generated by migy (https://github.com/makiuchi-d/migy)
CALL _migration_exists(10);
DELETE FROM _migrations WHERE id = 10;
-- Write your rollback SQL statements below.
DROP TABLE users;
$ migy check
applying: 000000_init.all.sql
---- up/down
applying: 000010_add_users_table.up.sql
applying: 000010_add_users_table.down.sql
checking...
ok
今度はチェックを通過しました。
migyのチェックは、テーブルの有無やスキーマ構造だけでなく、テーブルに含まれるレコードの差分も検出します。
ただし、単純にレコードを比較してしまうと、up.sqlで削除したカラムをdown.sqlで復元した場合に
元のデータが消えてしまっているため、すべてのレコードが差分ありとして検出されてしまいます。
このような場合に備え、down.sqlにmigy:ignore table.columnのようなコメントを書くことで、
特定のカラムを無視して差分検出する機能もあります。
詳しくはmigyのREADME.mdをご覧ください。
4. snapshot: スキーマ全体をダンプ
$ migy snapshot
applying: 000000_init.all.sql
applying: 000010_add_users_table.up.sql
========
writing: 000010_add_users_table.all.sql
snapshotサブコマンドは、マイグレーションを順に適用し、
最終的なDBの状態をall.sqlとして出力します。
今回の状態では、出力されたファイルはリスト11のようになっています。
_migrationsテーブルに履歴レコードが挿入され、
usersテーブルが作られていることがわかります。
▼リスト11: 000010_add_users_table.all.sql
-- Generated by migy (https://github.com/makiuchi-d/migy)
CREATE TABLE `_migrations` (
`id` int NOT NULL,
`applied` datetime,
`title` varchar(255),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
INSERT INTO `_migrations` (`id`,`applied`,`title`) VALUES
(0, '2025-11-04 14:35:19', 'init'),
(10, '2025-11-04 14:35:19', 'add_users_table');
CREATE TABLE `users` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
DELIMITER //
CREATE PROCEDURE _migration_exists(IN input_id INTEGER)
BEGIN
IF NOT EXISTS (SELECT 1 FROM _migrations WHERE id = input_id) THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'migration not found';
END IF;
END//
DELIMITER ;
このようにマイグレーション適用済みの状態でのスナップショットができるので、
ALTER TABLE文を積み重ねていても最終的なテーブルの構造がこのファイルを見ればわかります。
加えて、コンテナなどで開発環境を頻繁に新しく立ち上げる場合でも、
最新のスナップショットからマイグレーションすることで素早くDBを準備できます。
5. apply/list: マイグレーションの適用とリストアップ
applyサブコマンドは、引数で指定されたDBにmigyが直接接続し、必要なマイグレーションを適用します。
この方法は他の一般的なマイグレーションツールと同様です。
しかし、migyの主目的は「SQLによるマイグレーション」のサポートです。
サーバー上にmigyコマンドがなくても、SQLファイルだけでマイグレーションできるのが強みです。
ここで役に立つのがlistサブコマンドです。
まずサーバー上でmysqldumpコマンドを使って_migrationsテーブルをダンプし、その結果をdump.sqlとします。
ここでは例として、000000_init.all.sqlのみ適用した状態のdump.sqlを用意しました1。
次のようにmigy listを実行すると、マイグレーションに必要なSQLファイルが適用すべき順序で列挙されます。
$ migy list dump.sql
000010_add_users_table.up.sql
このSQLファイルをサーバーにコピーしてリストの順にmysqlコマンドで適用していけば、
サーバー上にmigyコマンドをインストールしなくても、マイグレーションを完遂できます。
ここで、listの実践的な使い方をひとつ紹介します。
MySQLには、.mylogin.cnfにログイン情報を暗号化して保存することで、
パスワードを明示せずにmysqlコマンドでDBに接続できるようにする機能があります。
筆者も実際に、本番DBのパスワードを知らされていない状態2で運用オペレーションを行っています。
パスワードがわからないので、MySQL標準コマンド以外のツールはDBに接続できず利用が難しいですが、
migyならlistで必要なSQLファイルを列挙し、それを順にmysqlコマンドに流し込むだけでマイグレーションを実行できます。
例として、筆者が本番環境で行っているマイグレーションコマンド3を次に示します。
サーバー上にmigyコマンドは用意されているので、パイプでmysqlコマンドにSQLを流し込んでいます。
mysqldumpとmysqlコマンドは.mylogin.cnfを読み取ってDBに接続するので、パスワードを知る必要はありません。
$ mysqldump _migrations > dump.sql
$ migy list dump.sql | xargs cat | mysql
技術の寿命から考えるSQLマイグレーションの合理性
技術の寿命に目を向けると、SQLでマイグレーションを行う合理性が見えてきます。
サービスが終了したあともデータは活用され続けることからわかるとおり、 データの寿命がとても長いことはよく知られています。 では、スキーマの寿命はどうでしょうか。
まずはDBについて考えてみましょう。 これまでもオンプレからクラウド、 最近では分散DBへの移行というムーブメントがみられます。 このように、データの寿命よりは短いかもしれませんが、 DBも数年から十数年単位という長いライフサイクルをもっていると言えます。
DBを移行する場合、主キーの選び方や制約の調整など、 スキーマも適した構造に作り直してこそ、DB本来の性能を発揮できるようになります。 つまり、スキーマはDBと同じ寿命をもっているものなのです。
ではフレームワークやアプリケーションコードの寿命はどうでしょうか。 セキュリティやパフォーマンス、スケーラビリティなどの要件の変化にあわせて、 フレームワーク、あるいは実装言語そのものを入れ替えるという話は、 技術系カンファレンスでよく語られるテーマです。 この場合、多くのプロジェクトで既存のDBを維持したまま、 アプリケーションを置き換えるという戦略がよく取られます。 このことからも、DBよりもフレームワークやアプリコードのほうが寿命が短いとわかります。 アプリが利用するライブラリやツールがさらに短命であることは言うまでもありません。
ここからわかるように、スキーマはDBとともに生きるものであり、 アプリコードやフレームワークより寿命がずっと長いものなのです。 そんなスキーマを管理するなら、寿命の短い技術に依存するのではなく、 DBと同じく長く生きる形式、すなわちSQLを使うのが合理的です。 SQLによるマイグレーションならば、アプリコードが寿命を迎えても、 DBが生きている限り同じようにスキーマを管理し続けられるでしょう。
歴戦のエンジニアなら一度は、「このSQLをORMでどう書けばいいのか」と悩んだり、 「この条件ならSQLで書いたほうが早い」と感じたことがあるでしょう。 複数のプロジェクトを渡り歩いてさまざまな言語やフレームワークを使っても、 根底にはいつも同じようにSQLがいます。 SQLは時代が変わっても陳腐化しにくい技術なのです。
どんな言語やフレームワークを使っていてもSQLを理解していれば、 データ構造を読み解き、性能を診断し、正しいスキーマを設計できます。 マイグレーションをSQLで書くということは、単にDBを操作するというだけでなく、 時代を超えて生き続ける知識と道具を手に入れることでもあります。
おわりに
マイグレーションは、単なるスキーマ変更の履歴ではなく、 アプリケーションとDBの関係の歴史そのものです。 だからこそ、変化の早いアプリケーション側の技術よりも、 DBと同等に長く安定して使えるSQLという共通言語で記述する意義があります。
SQLによるマイグレーションは、一見すると原始的で手間のかかる方法に見えるかもしれません。 しかし、スキーマの寿命がDBのそれと同じであることを考えれば、 その管理にDBと密接に関連する言語であるSQLを使うのは合理的な選択です。 スキーマの変更履歴を、アプリケーションのコードやフレームワークに縛られず、 純粋にDBの視点で残せるという点でも価値があります。
SQLでマイグレーションを書くことは、変化の制御をアプリケーションから切り離し、 データの永続性に責任を持つという選択です。 そのための一助として、SQLの力を素直に活かせる道具を手に取ってもらえれば幸いです。